Haiku 4.5 — vanilla vs down-skilled (experiment archive)
Supporting data for the blog post When down-skilling makes Haiku worse. The experiment ran in three rounds; each round adds tasks or scales sample size.
Round 1 — n=1 probe (3 tasks)
- RESULTS.md — qualitative findings across triage, code review, and voice rewrite. The initial probe.
- GUIDE.md — practitioner takeaways.
- prompts/ — vanilla and down-skilled prompts for each task.
- outputs/ — Haiku outputs from the n=1 run.
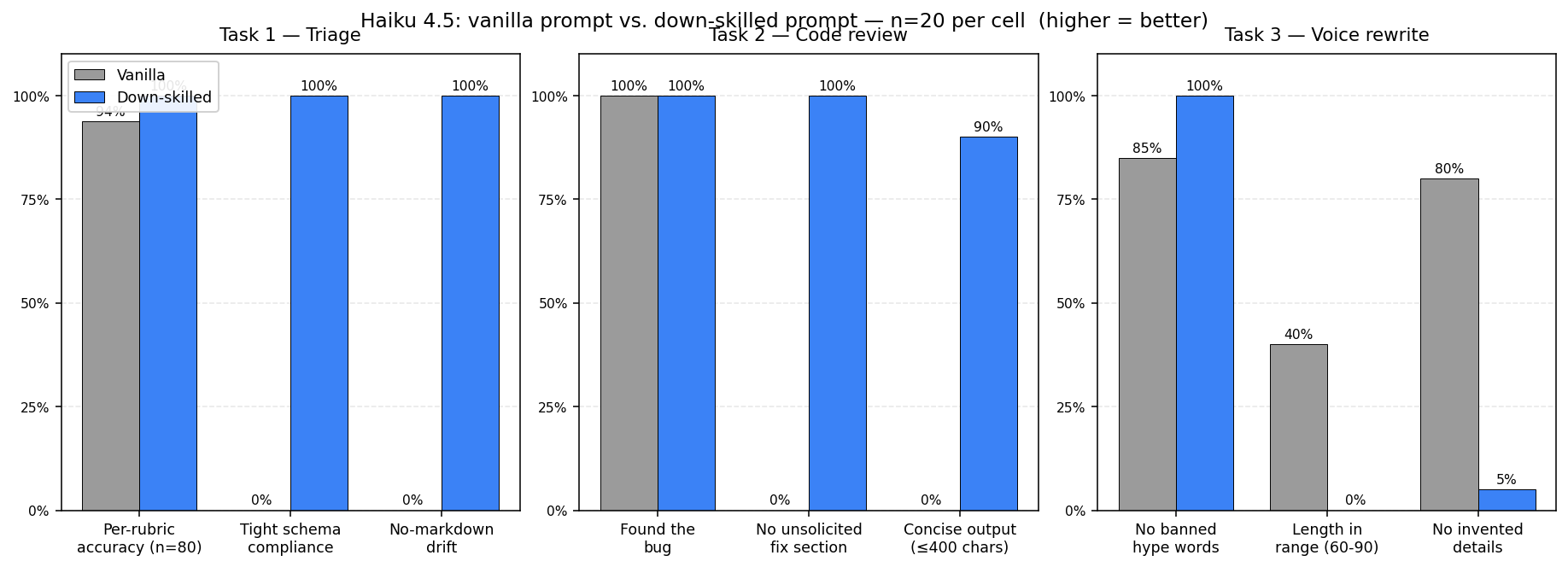
Round 2 — n=20 scaling (same 3 tasks)
- n20/RESULTS-n20.md — quantitative scaling. This is where the 19/20 hallucination finding lives.
- n20/scores.json — raw metrics.
- n20/score.py — scoring rubric code.
- n20/chart.py — chart generation.
- n20/comparison.png — visual comparison.
- n20/outputs/ — all 120 Haiku outputs.
{kind=link}
Round 3 — broader probe (5 new tasks + T3b calibrated rerun)
- n20/broader/RESULTS-broader.md — JSON extraction, changelog generation, sort-and-filter, NL→CLI, copyedit, plus the T3b voice-rewrite rerun with calibrated examples.
- n20/broader/proposed-skill-patch.md — the patch that became down-skilling v1.2.0.
- n20/broader/prompts/ — including the calibrated T3b prompt.
- n20/broader/outputs/ — Haiku outputs for the broader probe.
- n20/broader/scores.json, score.py — raw metrics + rubric.
Files are markdown / JSON / Python served raw. The narrative reads cleanest in this order: RESULTS.md → n20/RESULTS-n20.md → n20/broader/RESULTS-broader.md.